





Macros en Nim
El concepto de macro en el lenguaje de programación Nim es al mismo tiempo simple, complicado y absolutamente genial. No tiene nada que ver con las macros de C (lo más parecido en Nim son los templates).
Es «simple» porque las macros en Nim son simplemente «código Nim que produce código Nim», o más bien, un AST (Abstract Syntax Tree) que se traduce a otro AST.
Para seguir con mi aprendizaje Nim e intentar usarlo como algo diferente, en lugar de un simple sustituto de PHP o Python, necesitaba comprender -al menos algo- de las macros. Se me ha presentando la oportunidad al intentar reproducir una librería PHP que estoy utilizando en el puente Telegram<>XMPP, que es https://github.com/elvanto/litemoji. Esta librería se encarga de traducir emojis UTF8 a códigos cortos, y viceversa.
Podemos encontrar los emoji habidos y por haber en el proyecto emojibase. Los ofrece divididos por idiomas y en formato JSON. Yo utilizo data.raw.json.
Lo sencillo sería incorporar ese fichero JSON al proyecto y, en cada ejecución del traductor a shortcodes, analizarlo para encontrar la correspondencia. Pero si lo pensamos un poco mejor, este fichero no cambia con frecuencia, y la operación de parsing y búsqueda de cada emoji es costosa. Por tanto, podríamos hacerlo solo una vez en tiempo de compilación y dejarlo plasmado en una función creada mediante una macro.
Lo que queremos hacer, expresado a lo bestia, es como si abriéramos ese JSON en un editor y en el editor de Nim fuéramos escribiendo a mano una sentencia case por cada objeto presente en el fichero, pero como eso sería extremadamente tedioso, lo hacemos con una macro. Por ahora nos vamos a centrar solo en la parte que traduce desde un emoji a su código hexadecimal.
Hay muchas formas de escribir código Nim que produce código Nim y están muy bien explicadas aquí https://nimprogrammingbook.com/book/nimprogramming_rouge_molokai.html#_macros_and_meta_programming (recomiendo encarecidamente la compra de este libro). La más flexible es la creación iterativa manual, donde vas añadiendo nodos que representan cada una de las partes de las instrucciones https://nimprogrammingbook.com/book/nimprogramming_rouge_molokai.html#_building_the_ast_manually. El problema es que es muy difícil comenzar.
Afortunadamente, Nim nos proporciona mucha ayuda en este sentido. Pensemos primero en la estructura que tiene el fichero JSON y lo que nosotros queremos producir
{
"label": "cara sonriendo con ojos sonrientes",
"hexcode": "1F604",
"emoji": "😄",
"text": "",
"type": 1,
"order": 3,
"group": 0,
"subgroup": 0,
"version": 0.6,
"emoticon": ":D"
},
{
"label": "cara radiante con ojos sonrientes",
"hexcode": "1F601",
"emoji": "😁",
"text": "",
"type": 1,
"order": 4,
"group": 0,
"subgroup": 0,
"version": 0.6
},Este es un fragmento simplificado del fichero JSON es/data.raw.json. El original supera las 55 mil líneas, describiendo todos los datos de los emoji que existen. Si tuviéramos que expresar ese conocimiento en código (ya sea Nim o cualquier otro) podríamos hacerlo de muchas formas diferentes; yo he optado por una sentencia case.
proc emojiToHex(emoji: string): string =
case emoji:
of "😄":
result = "1F604"
of "😛":
result = "1F601"¿Simple, no? Este es un traductor de emoji a código hexadecimal perfectamente válido, que expresa el conocimiento contenido en el fragmento de más arriba. Como decía, podríamos pasarnos un mes escribiendo esta función, pero acto seguido deberíamos abandonar la profesión para ingresar en un psiquiátrico.
Cuando escribimos el fragmento anterior ¿qué AST produce Nim cuando lo compila? Eso es lo que necesitamos saber. Para ello, nos proporciona la macro dumpAstGen.
import std/macros
dumpAstGen:
proc emojiToHex(emoji: string): string =
case emoji:
of "😀":
result = "1F604"
of "😛":
result = "1F601"La compilación de este programa es muy interesante, porque nos imprime el resultado del análisis de este código, pero como código Nim válido:
nnkStmtList.newTree(
nnkProcDef.newTree(
newIdentNode("emojiToHex"),
newEmptyNode(),
newEmptyNode(),
nnkFormalParams.newTree(
newIdentNode("string"),
nnkIdentDefs.newTree(
newIdentNode("emoji"),
newIdentNode("string"),
newEmptyNode()
)
),
newEmptyNode(),
newEmptyNode(),
nnkStmtList.newTree(
nnkCaseStmt.newTree(
newIdentNode("emoji"),
nnkOfBranch.newTree(
newLit("😀"),
nnkStmtList.newTree(
nnkAsgn.newTree(
newIdentNode("result"),
newLit("1F604")
)
)
),
nnkOfBranch.newTree(
newLit("😛"),
nnkStmtList.newTree(
nnkAsgn.newTree(
newIdentNode("result"),
newLit("1F601")
)
)
)
)
)
)
)Como podemos observar, para un novato en macros Nim, sería muy difícil llegar a este código desde cero.
El estilo de salida de la macro dumpAstGen es por composición, pero nuestro objetivo es crear ese código de forma dinámica, iterando a través de los elementos del fichero JSON. El código anterior se puede expresar de forma iterativa creando nodos y añadiendo nodos a los nodos, pero al principio puede ser difícil transformar el código anterior (correcto) a un estilo iterativo. Lo más fácil en este caso es localizar la parte variable en esa estructura y dejar todo lo demás igual, de forma que este sería el primer paso de la transformación:
caseStaments = ...
nnkStmtList.newTree(
nnkProcDef.newTree(
newIdentNode("emojiToHex"),
newEmptyNode(),
newEmptyNode(),
nnkFormalParams.newTree(
newIdentNode("string"),
nnkIdentDefs.newTree(
newIdentNode("emoji"),
newIdentNode("string"),
newEmptyNode()
)
),
newEmptyNode(),
newEmptyNode(),
nnkStmtList.newTree(
caseStatements
)
)
)Lo único que va a variar de nuestro case si varía el fichero JSON es la secuencia de sentencias of. Lo siguiente que haremos será componer lo que ya teníamos en términos del estilo iterativo:
macro emojiToHex(): untyped =
echo "Creando la función emoji2Hex"
var caseStatements = nnkCaseStmt.newTree()
caseStatements.add(newIdentNode("emoji"))
caseStatements.add(nnkOfBranch.newTree(
newLit("😀"),
nnkStmtList.newTree(
nnkAsgn.newTree(
newIdentNode("result"),
newLit("1F604")
)
)
))
caseStatements.add(nnkOfBranch.newTree(
newLit("😛"),
nnkStmtList.newTree(
nnkAsgn.newTree(
newIdentNode("result"),
newLit("1F601")
)
)
))
nnkStmtList.newTree(
nnkProcDef.newTree(
newIdentNode("emoji2Hex"),
newEmptyNode(),
newEmptyNode(),
nnkFormalParams.newTree(
newIdentNode("string"),
nnkIdentDefs.newTree(
newIdentNode("emoji"),
newIdentNode("string"),
newEmptyNode()
)
),
newEmptyNode(),
newEmptyNode(),
nnkStmtList.newTree(
caseStatements
)
)
)
emojiToHex()
echo emoji2Hex("😛")
En este último fragmento vemos ya la definición de la macro, su ejecución (que lo que hace es crear la función emoji2Hex) y la ejecución de emoji2Hex. Hemos creado una función que se ejecuta en tiempo de compilación (una macro) que crea una función destinada a ejecutarse en tiempo de ejecución, disponible en el ámbito general. Si tu editor tiene un comprobador de la sintaxis, verás que no se queja porque la función emoji2Hex no exista. De hecho, no hemos declarado ningún proc con ese nombre, pero saber ver que la macro creará esa función.
Aquí vemos el resultado de la compilación:
nimdev:/var/local/codigo/nimdev/prosody2email2# nim c --verbosity:0 --hint[Processing]:off --excessiveStackTrace:on macrodump.nim
Creando la función emoji2Hex
El hecho de que aparezca ese mensaje prueba que la macro se ha ejecutado en tiempo de compilación. Y aquí tenemos el resultado de la ejecución del programa compilado:
nimdev:/var/local/codigo/nimdev/prosody2email2# ./macrodump
1F601Donde se puede observar el resultado de la llamada echo emoji2Hex("😛").
Para finalizar, solo tenemos que hacer que la macro sea capaz de leer el fichero JSON con los emoji y de crear una función emoji2Hex completa. Este es el código que nos falta (recortada la parte final):
macro emojiToHex2(): untyped =
var caseStatements = nnkCaseStmt.newTree()
caseStatements.add(newIdentNode("emoji"))
let path:string = "./data.raw.json"
echo "Creando la función emoji2Hex con " & path
let jsonHexStr = staticRead(path)
let jsonHex = parseJson(jsonHexStr)
for emoji in jsonHex:
let emojiStr: string = getStr(emoji["emoji"])
let emojiHex: string = getStr(emoji["hexcode"])
caseStatements.add(nnkOfBranch.newTree(
newLit(emojiStr),
nnkStmtList.newTree(
nnkAsgn.newTree(
newIdentNode("result"),
newLit(emojiHex)
))))
nnkStmtList.newTree( ...Se compila y ejecuta y tenemos la salida de un par de nuestros emoji:
nimdev:/var/local/codigo/nimdev/prosody2email2# nim c --verbosity:0 --hint[Processing]:off --excessiveStackTrace:on macrodump.nim
Creando la función emoji2Hex con ./data.raw.json
nimdev:/var/local/codigo/nimdev/prosody2email2# ./macrodump
😛1F61B
🤣1F923
Como no estaba seguro de que esta fuera la solución correcta, concretamente de que la ejecución del programa compilado no estuviera también leyendo el fichero JSON, pasé a comprobarlo. Si elimino data.raw.json no compila:
nimdev:/var/local/codigo/nimdev/prosody2email2# nim c --verbosity:0 --hint[Processing]:off --excessiveStackTr
ace:on macrodump.nim
Creando la función emoji2Hex con ./data.raw.json
/var/local/codigo/nimdev/prosody2email2/macrodump.nim(45, 12) template/generic instantiation of `emojiToHex2` from here
/var/local/codigo/nimdev/prosody2email2/macrodump.nim(10, 30) Error: cannot open file: ./data.raw.jsonPero veamos qué pasa con la ejecución:
nimdev:/var/local/codigo/nimdev/prosody2email2# ./macrodump
😛1F61B
🤣1F923
Sigue funcionando. Todo el conocimiento del fichero JSON está incorporado al binario macrodump. La única desventaja de este enfoque es que el ejecutable es muy grande. A mi me da 972Kb en Linux/AMD64, y es un programa muy sencillo. Pero creo que compensa cuando lo importante es la velocidad de ejecución y el ahorro de memoria.
Para saber si algo ha merecido la pena tenemos que medir, siempre hay que medir. Veamos tres ejecuciones de la versión en PHP y tres ejecuciones de la versión Nim, midiendo el tiempo empleado:
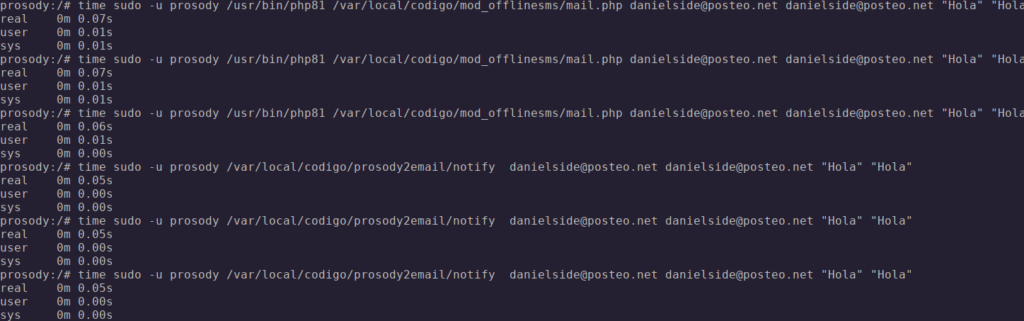
No es demasiada ganancia en un programa tan pequeño, pero se puede ver que hay mejora.
Valgrind nos puede ayudar a averiguar el perfil de uso de memoria de cada programa (heap y stack):
valgrind --tool=massif /usr/bin/php81 /var/local/codigo/mod_offlinesms/mail.php danielside@posteo.net danielside@posteo.net "Hola" "Hola"El resultado se guarda en un archivo y se puede imprimir un resumen con ms_print:
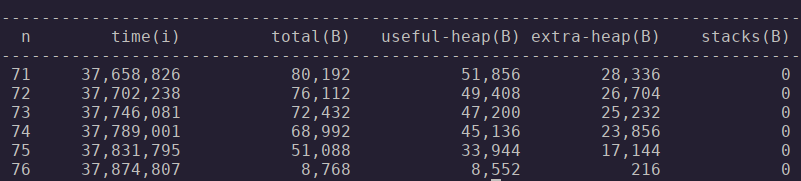
Lanzamos lo mismo para la versión Nim y tenemos el siguiente resultado:

En toda la ejecución, la versión PHP ha fluctuado entre 8K y 80K de uso de heap, y la versión Nim entre 15K y 67K. El heap es la estructura donde se va creando espacio en memoria RAM cuando un programa va solicitando memoria de forma dinámica. Es más costoso porque el sistema operativo no sabe cuanta memoria va a necesitar el programa y tiene que ir buscando continuamente huecos libres. El stack queda predeterminado al comienzo de la ejecución y es el área en RAM donde se almacenan aquéllos objetos de los cuales se sabe al principio cuanto espacio van a necesitar. Los lenguajes interpretados hacen un uso desmedido del heap, porque prácticamente todas las asignaciones de memoria ocurren en tiempo de ejecución.
Si añadimos --stacks=yes a Valgrind tenemos un análisis del tamaño ocupado por el stack en el programa Nim:

Y en el programa PHP:

Estas dos últimas capturas son las importantes, ya que aúnan el profiling tanto de stack como de heap. Ahí se ve que para un programa tan insignificante PHP ha llegado a consumir 1,6M de RAM, mientras que (en esa ejecución) la versión Nim solo 28K.
Código final: https://git.sr.ht/~danielside/prosody2email
Perpetrado el 19 de julio de 2024 por una IN (Inteligencia Natural), la mia, con cierto esfuerzo.
Archivado en categoría(s) Nim, Programación
Deja una respuesta