





Mejorando el rendimiento de procesamientos con PHP
Le he dado el nombre de «procesamientos» para referirme a procesos largos que se ejecutan fuera del marco de la web. En otros tiempos diríamos «procesos batch» pero queda viejuno y windowsiano. Y «procesos» queda muy genérico.
El uso más extendido de PHP es procesar información en el backend, con la ayuda de FPM, para devolver contenido a un servidor web y éste a su vez devolver HTML al cliente. Pero en sistemas web complejos, tarde o temprano necesitaremos procesar cosas (ficheros grandes, tareas de mantenimiento, tareas de envíos de comunicaciones a clientes, etc). Este tipo de tareas es muy sensible a las mejoras que vamos a comentar en este post.
Como se compila PHP
Se suele decir que PHP es un lenguaje interpretado, en contraposición a lenguajes como C, que son compilados. Como no todo es blanco o negro, os contaré la verdad: todos los lenguajes son compilados, ya que si no no se podrían ejecutar en una CPU.
La diferencia fundamental es el momento en el que se compilan. Un lenguaje como C pertenece a la categoría de los compilados «Ahead Of Time», es decir, antes de su ejecución. Y PHP moderno primero «compila» a un código intermedio (opcodes) que finalmente la máquina virtual Zend volverá a compilar a código máquina. Es parecido al código intermedio Java de la JVM (Java Virtual Machine). Este código intermedio escrito con opcodes es portable entre sistemas operativos y arquitecturas y sus instrucciones se parecen mucho a las del código ensamblador.
Lo que globalmente conocemos como «compilar» (dejando aparte optimizaciones) conlleva una amplia variedad de fases intermedias, siendo la primera de ellas el análisis léxico del fichero de entrada. Antes de generar el código que entiende la máquina (ensamblador) se ha hecho un trabajo previo con el fichero para dejarlo más manejable.
Un fichero PHP pasa por las fases de análisis léxico, creación de tokens, construcción de AST (Abstract Syntax Tree) y finalmente de ahí salen las oplines (las líneas completas con sus operandos son oplines, opcode es el código de la instrucción de la máquina virtual Zend).
Según hemos ido viendo nuevas versiones de PHP, se han desarrollado dos técnicas importantes de cara al rendimiento de la compilación PHP:
- OPcache. A partir de PHP 5.5 esta interesante extensión venía ya incluída en PHP. Guarda los scripts ya analizados en memoria, de manera que cada vez que se cargue un script PHP no tiene por qué volver a pasar por las fases de análisis léxico, tokenización y AST, si este script no ha cambiado.
- JIT. A nivel de opcode, OPCache ya puede realizar algunas optimizaciones (eliminación de código muerto, por ejemplo). Pero el siguiente paso natural para alcanzar la mayor eficiencia sería (en PHP 8.0) la de ignorar por completo la máquina virtual (Zend Engine). La compilación JIT (Just In Time) se hace durante la fase de ejecución y permite compilar directamente a código máquina y cachearlo.
JIT se ofrece como parte de OPCache.
Las mayores ventajas de utilizar estos dos subsistemas nos las vamos a encontrar cuando ejecutamos código que se repite mucho, durante mucho tiempo dentro de un mismo proceso. Es decir, que para un ciclo normal de petición/respuesta HTTP puede que no veamos mucha mejora (no se llega a aprovechar bien el código precompilado cacheado).
El ejemplo
El código que genera la base de datos de https://puestosdetrabajofuncionarios.nom.es/ es un excelente ejemplo de lo que comento de proceso largo y repetitivo que se puede beneficiar -potencialmente- de OPCache y JIT, ya que va a pasar cientos de veces por las mismas instrucciones. Este código inserta alrededor de 190.000 registros en una base de datos MySQL.
Evidentemente, antes de comenzar con técnicas de optimización como las que vamos a explicar, lo primero que tenemos que conseguir es un algoritmo muy optimizado. Hay varias maneras de realizar una extracción/inserción de estas características. Podría haber optado por realizar una pasada para insertar todos los ministerios, otra pasada por todos los ficheros para insertar todos los centros directivos, etc y una pasada final para todos los puestos. Pero en principio me pareció que iba a ser más eficiente hacer una sola pasada para todo.
La primera idea (inocente) que se nos viene a la cabeza es «por cada puesto, si encuentro insertado el ministerio en la base de datos lo uso y si no, lo inserto nuevo». Pero esto genera una cantidad enorme de consultas innecesarias. Así que opté por declarar una estructura en memoria (con arrays) replicando esa información. Por cada entidad asociada al puesto (ministerio, centro directivo, unidad) consulto si la tengo en memoria y si no, la inserto y la marco en ese array como insertada, almacenando su identificador. Al precio de usar más memoria, consigo más velocidad. El funcionamiento en general es como sigue:
- Convierte una hoja Excel a CSV. Cada línea contiene un puesto de trabajo. Cada puesto de trabajo contiene datos para la tabla puesto (nombre, nivel, grupo, complemento específico, vacante y forma de provisión) y datos para crear las relaciones con otras tablas (ministerio/organismo, centro directivo, unidad, país, provincia, localidad).
- En cada fila, por cada uno de los datos que conforman una relación con otra entidad, pueden pasar dos cosas:
- Que ya haya pasado por un puesto de esa misma unidad, centro directivo o ministerio y por tanto no haya que insertarlo. Obtengo su identificado de la estructura almacenada en memoria.
- Que no haya pasado todavía por un puesto de esa unidad, o centro, o ministerio, y por tanto haya que insertar alguno de ellos o todos ellos. En ese caso guardo en base de datos y marco en memoria como insertado.
Para hacer una primera evaluación de lo que tengo, utilizo la herramienta time de Linux para medir el tiempo que tarda el proceso sin optimizaciones. Todas las pruebas se realizan en una máquina virtual KVM Debian 11 con dos procesadores a 3Ghz y 8G de RAM. Entre prueba y prueba reinicio la máquina virtual Debian.
Tiempo sin optimizaciones:
time php parse.php --rpt=rpt202306 ...Resultado:
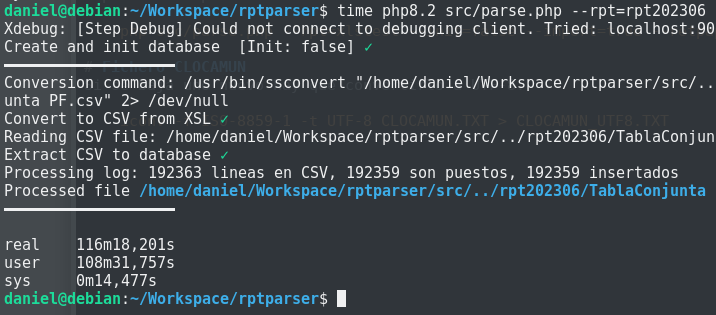
Ahora vamos a realizar una importación activando OPCache y JIT. Normalmente se activaría modificando el fichero php.ini correspondiente, pero para el propósito de esta prueba nos basta pasarle esas opciones a php directamente. Esta es la llamada:
time php \
-dopcache.enable_cli=1 \
-dopcache.jit_buffer_size=256M \
-dopcache.jit=1255 \
-dxdebug.mode=off parse.php --rpt=rpt202306 ...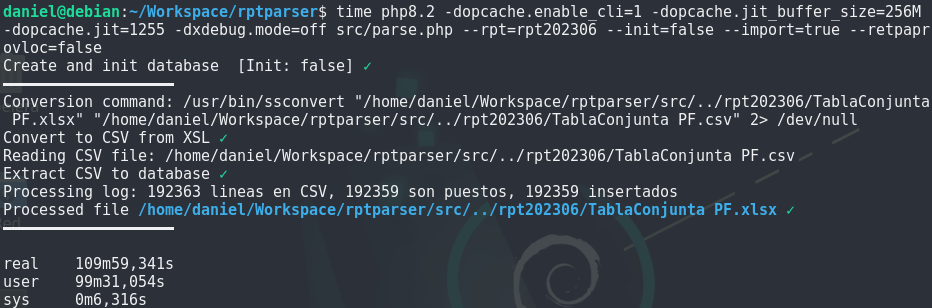
Hemos realizado una importación dedicándole 256M de RAM para almacenar código compilado y con las opciones recomendadas 1255:
- 1 – Activar el uso de las instrucciones AVX si lo soporta la CPU (extensiones vectoriales, útiles por ejemplo en procesamiento gráfico o cálculo en general).
- 2 – Localización global de registros
- 5 – «Tracing JIT», que perfila sobre la marcha y detecta secciones de «código caliente» para optimizar.
- 5 – Optimizar el script completo
Todas las opciones de configuración están aquí https://www.php.net/manual/en/opcache.configuration.php#ini.opcache.jit pero para entenderlas a fondo hay que comprender bien como funciona JIT, lo cual se explica bastante bien en el enlace 1, en «Lectura adicional».
Unos 7 minutos de ganancia no está mal, pero no es espectacular, veamos de qué manera podríamos ayudar a JIT a optimizar más.
Mejoras adicionales
Strict Typing
Podemos ayudar a la compilación JIT siendo más estrictos con los tipos de datos, especialmente los argumentos de las funciones. Llamar a una función en cualquier lenguaje es algo costoso: se debe vaciar el cauce de ejecución, crear un registro de activación, crear un stack, reservar espacio para los argumentos y las variables locales, como mínimo. Es obvio que no podríamos vivir sin funciones/procedimientos/métodos porque crearíamos software imposible de mantener, pero podemos ayudar a que sean más llevaderas para el procesador.
En el segundo parámetro de la configuración de jit «1255» le estábamos diciendo que guardara valores en registros de la CPU a nivel global. Si el compilador no sabe el tamaño de los argumentos de las funciones, no puede guardar sus valores en registros (la memoria más rápida que existe), por tanto tenderemos a escribir todas las funciones con tipos de datos manejables (que quepan en un registro), en número aceptable (mejor funciones con pocos argumentos) y con indicación del tipo de datos (type hint)
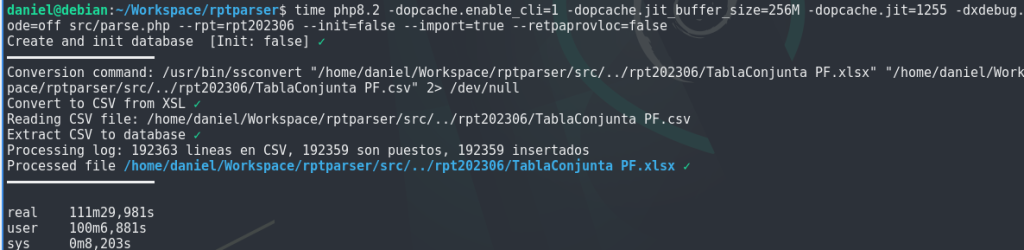
Podemos ver como, al menos en esta ejecución, no ha mejorado lo que ya teníamos. Aun así, mejora respecto a la situación inicial. Esto puede deberse a varios factores: no ha sido posible optimizar tanto como se pensaba con las funciones (asignación de argumentos a registros), no hemos recorrido todo el código haciendo estos type hints, o bien la mejora en sí no ha sido tan sustanciosa. De todas formas, es un cambio que merece la pena hacer por legibilidad del código y testing.
Pero ¿qué está pasando realmente en este código?
Habiendo agotado posibilidades de optimización sin cambiar la lógica, tenemos que centrarnos en el algoritmo.
Primero hay que mirar los bucles y aquí el más importante es el que recorre todas las líneas de cada fichero CSV exportado desde Excel. ¿qué estamos haciendo aquí que puede ser tan pesado?
Tengo que culpar a mi yo del pasado. La idea de guardar en memoria un registro de los registros que se iban insertando estaba bien -ahorro de consultas- pero no estaba bien ejecutada. En la versión inicial estaba manejando una matriz, donde la primera dimensión es el tipo de entidad («puesto», «ministerio», «unidad», etc) y la segunda el identificador del mismo:
function register($entidad, $clave) {
if (!key_exists($entidad, $this->inserted)) {
$this->inserted[$entidad] = array();
}
$this->inserted[$entidad][] = $clave;
}
function isRegistered($entidad, $clave) {
if (!key_exists($entidad, $this->inserted)) {
return FALSE;
}
$elementsInserted = $this->inserted[$entidad];
$inserted = FALSE;
if (!empty($elementsInserted) && is_array($elementsInserted)) {
foreach($elementsInserted as $claveInsertada) {
if ($claveInsertada == $clave) {
$inserted = TRUE;
break;
}
}
}
return $inserted;
}Y me dije «realmente, la combinación de $entidad y $clave es única, no hay necesidad de tener una matriz, ¿qué tal esto?
function register(string $entidad, string $clave)
{
$this->inserted[$entidad . $clave] = null;
}
function isRegistered(string $entidad, string $clave): bool
{
return key_exists($entidad . $clave, $this->inserted);
}
PHP implementa cualquier array como un map (tabla hash) y el acceso a esa primera dimensión de $inserted es muy rápido. Si la combinación $entidad y $clave es única, no necesito nada más, incluso no tengo que almacenar ningún valor en la posición, porque todo lo que pregunto es si la clave existe.
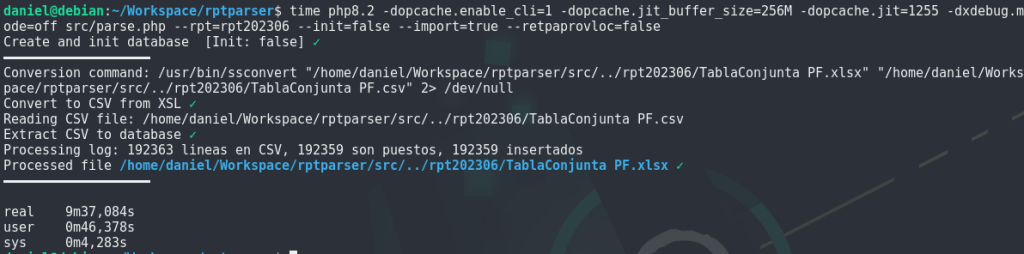
Ejecución de este código sin JIT:
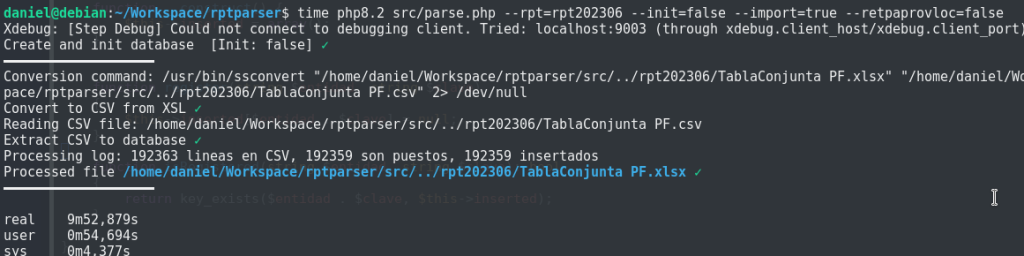
Y ahora una pasada con JIT activado:
Conclusiones
Espectacular la ganancia de optimizar el bucle principal, pasando de tiempos cercanos a las dos horas, a 10 minutos. Y no tan espectacular la ganancia con JIT. Aun así, merece la pena activarlo y ver como se comporta en tu problema concreto.
Lectura adicional
- https://php.watch/articles/jit-in-depth
- https://wp-rocket.me/wordpress-cache/what-is-opcache/
- https://luajit.org/dynasm.html
Perpetrado el 19 de junio de 2023 por una IN (Inteligencia Natural), la mia, con cierto esfuerzo.
Archivado en categoría(s) PHP, Programación
Deja una respuesta